

Uma coisa que experimentamos é que a maior parte do trabalho envolvido em tal projeto não está diretamente relacionado a problemas de aprendizado de máquina (ou pelo menos relacionado ao uso de algoritmos de aprendizado de máquina).
Então li recentemente uma pesquisa conduzida pela CrowdFlower em 2016 que apoia esta nossa experimentação.
Eles pesquisaram cerca de 80 cientistas de dados para sondá-los e descobrir “onde eles sentem que sua profissão está indo [e] como é o trabalho cotidiano deles”.
A pergunta: “O que os cientistas de dados gastam mais tempo fazendo” eles responderam:
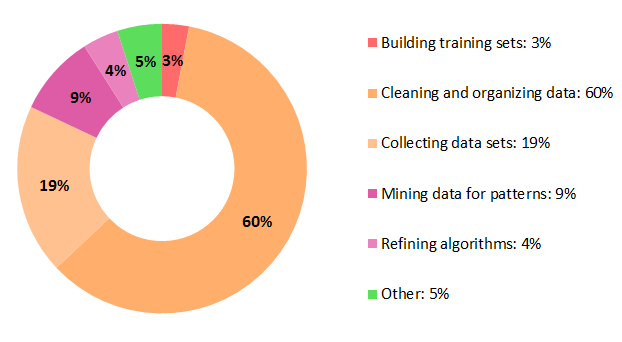
Como pode ser notado, 77% do tempo gasto por um cientista de dados está relacionado a seleção, teste e refinamento de algoritmos de aprendizado não-máquina.
Se ler a pesquisa, verá que, ao mesmo tempo, cerca de 93% dos entrevistados disseram que essas são as tarefas menos agradáveis! O que é um pouco deprimente.
Mas, por outro lado, não sabemos o quanto eles não gostaram dessas tarefas.
O que eu acho interessante na pesquisa é que a maioria dessas tarefas específicas de algoritmos de aprendizado não-máquina (mais uma vez, 77% delas!) são tarefas de manipulação de dados que precisam ser projetadas em algum processo / fluxo de trabalho / pipeline.
Para colocar esses números em contexto, abaixo um esquema geral de fluxo de trabalho de aprendizado de máquina.
Dependendo da tarefa, algumas etapas podem diferir e ser adicionadas, mas o núcleo está nesta imagem abaixo.
Observe também que todas as tarefas em que esse fluxo de trabalho de aprendizado de máquina foi usado estão relacionadas ao processamento de linguagem natural, à correspondência de entidades, aos conceitos e às entidades de marcação e desambiguação.
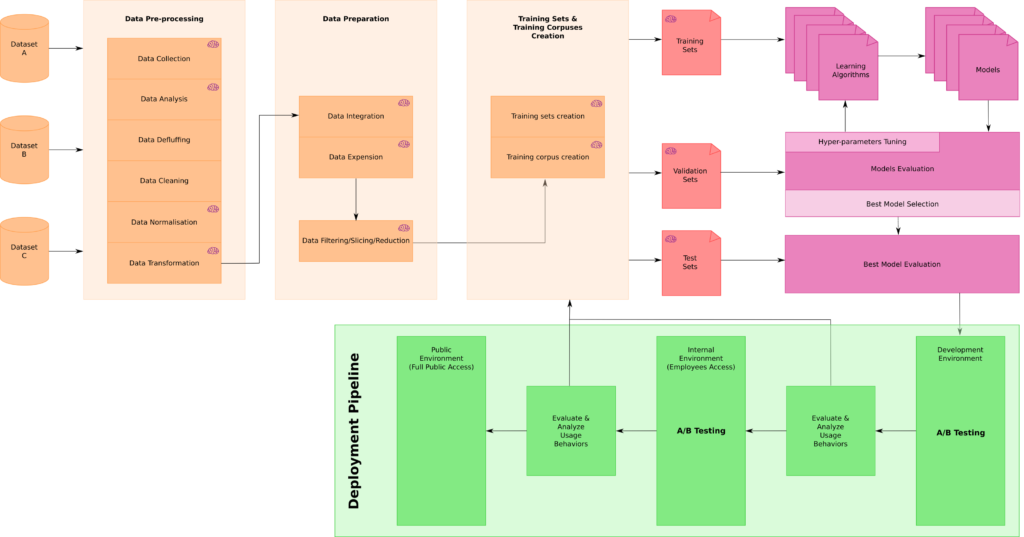
Esse fluxo de trabalho é dividido em quatro áreas gerais:
- Processamento de dados
- Criação de conjuntos de treinamento
- Teste, avaliação e seleção de Algoritmos de Aprendizado de Máquina
- Implantação e teste A / B
O único trabalho de aprendizado de máquina “real” acontece no canto superior direito deste esquema e incide apenas cerca de 13% do tempo gasto pelos cientistas de dados de acordo com a pesquisa.
Todas as outras tarefas estão relacionadas à aquisição de dados, análise de dados, normalização de dados, transformação de dados e integração de dados, filtragem de dados / fatiamento / redução com os quais criaremos uma série de diferentes conjuntos de treinamento ou corpus de treinamento que levarão à criação (após a divisão adequada) dos conjuntos de treinamento, validação e teste.
É somente nesse ponto que os cientistas de dados começarão a testar algoritmos para criar modelos diferentes, para avaliá-los e ajustar os hiper-parâmetros. Uma vez que o (s) melhor (s) modelo (s) é (são) selecionado (s), então gradualmente os colocamos em produção com diferentes etapas de teste A / B.

Artigos relacionados:
 Perguntas mais frequentes sobre Linux
Perguntas mais frequentes sobre Linux